Report 9
Maximilian Fernaldy - C2TB1702
Part 1 - Poisson Distribution
Introduction to the Poisson Distribution
The Poisson distribution expresses the probability of a given number of events happening in a certain amount of time, if they occur with a known, constant mean rate and the events are independent of each other (meaning, an event happening does not change the probability of more events happening after it).
The Poisson distribution can be expressed as an equation of probability of events happening in a fixed amount of time:
With as probability of events happening in time and as average number of events that has happened in time .
Something to note is that while can be any positive real number, is only defined for positive integers. Let's do an example problem to understand why this is.
An example
Suppose a restaurant is visited by customers per day on average. The restaurant is underground, so people can't see inside and consequently, how many customers are inside the store doesn't affect the probability of new customers visiting it.
We can then denote as the average amount of customers per day and as the reference time interval.
An investor is interested in purchasing part ownership of the restaurant for a single trial week, but he wants to know if the restaurant will turn a profit. To get any return on investment (ROI), the investor needs or more customers in that week. He has a statistician calculate the probability of this happening.
Now we can get a sense of why and has to be integers. It doesn't make sense to try and calculate the probability of, say, customers visiting the restaurant in a week. Events happen in integers: either they happen or they don't, 0 or 1.
The statistician uses the Poisson distribution to do the task assigned to them. They note that the investor wanted to know the probability of or more customers visiting the restaurant in days, which means an easy way to calculate this probability is to instead calculate the inverse probability, then subtract it from unity:
However, the statistician quickly realizes that plugging in these values one by one like this:
will take too long and it's too much work for how much they're getting paid. Instead, the statistician starts up Octave and writes this code to compute the probability:
lambda = 13.5 % Average events in reference time interval t0 = 1 % Reference time interval in days tq = 7 % Asked-for time interval t = tq/t0 % Time interval as expressed in multiple of t0 for i = 0:89 % Iterate from k = 0 to k = 89 % Use Poisson distribution formula p(i+1) = (e^(-lambda * t) * (lambda * t)^i) / factorial(i); endfor % Subtract sum of probabilities from unity to get answer 1 - sum(p)
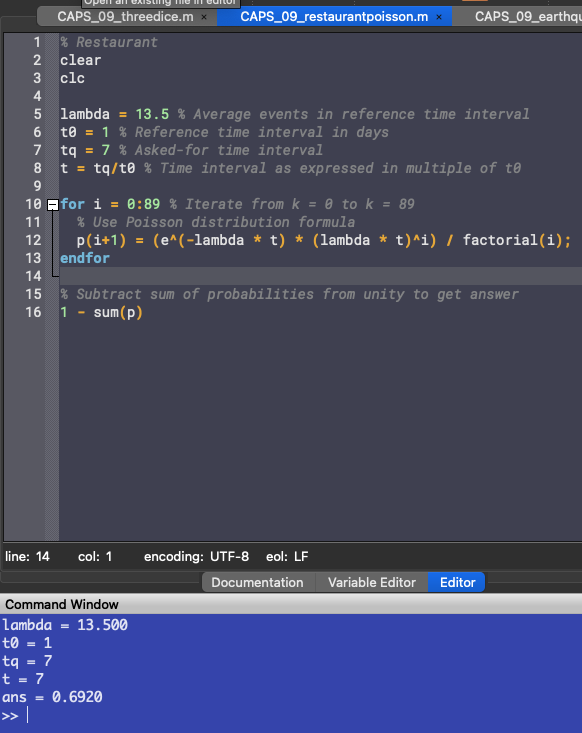
Apparently, the probability of 90 or more customers visiting the restaurant is . The investor is happy with this percentage, and goes through with his decision.
Solving Exercise 9.1

Parameters
My student number is C2TB1702.
- Earthquakes occur times in days on average.
- There were earthquakes in the last four weeks.
Applying Poisson Distribution
From parameter (1), and the reference time period is days. From parameter (2), and days.
We want to know , which we can calculate by subtracting its inverse from unity.
To calculate the inverse probability:
Because is defined for the reference time interval , to continue to use , we want to linearly adjust so that it is a ratio of and . We can do this by dividing by , which will leave use with the appropriate number for . In octave code:
lambda = 1.4; % Average number of earthquakes in 8 days t0 = 8; % Reference time period tq = 28; t = tq/t0; % Expressed as multiple of t0 k = 12; % Limiter for events for i = 0:k - 1 % Iterate from 0 to 11 prob(i+1) = (lambda * t)^i * e^(-lambda * t) / factorial(i); endfor
Then simply subtracting it from unity, we get the probability for 12 or more earthquakes happening :
probKAndMore = 1 - sum(prob)
which outputs
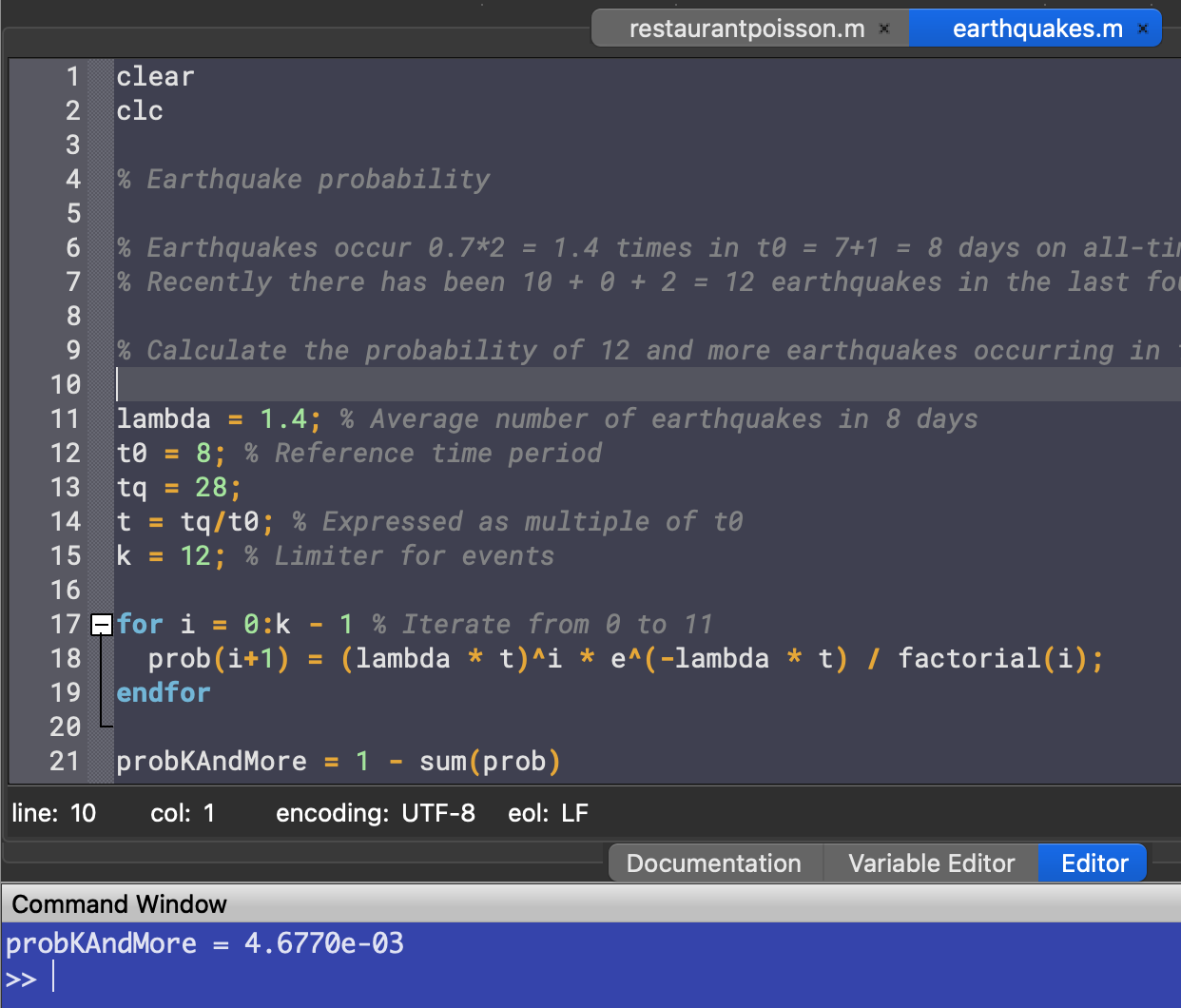
This means the probability of 12 earthquakes or more happening is very small under normal circumstances - smaller than . This suggests that something else might be at play, something out of the ordinary that caused the sudden jump in earthquake frequency.
Part 2 - Three Dice

Parameters
The sum of the last 4 digits of my student number is .
Applying basic probability theory
When rolling three dice, the number of possible sums is actually only . The lowest possible sum is and the highest possible sum is . Therefore there are only possible different sums. However, they have different odds of happening. For example, to get a sum of , there is only one possible combination of the three dice, that being all of them showing . On the other hand, there are many different combinations that result in a sum of . This means the probability of getting one sum is not equal to the others.
This is why when calculating the probability of getting a certain sum, we can't just say it's . We need to consider all the possible events and take note of the combinations that result in that sum.
Applying this to our problem, there are possible combinations of the three dice, and the possible events that result in a sum of 10 are:
- with unique numbers, so events
- with unique numbers, so events
- with a number appearing twice, so events
- with unique numbers, so events
- with a number appearing twice, so events
- with a number appearing twice, so events
Adding them all up, we have events. The probability of getting a sum of 10 is:
Using Octave to get the probability
Counting the different probable events one by one is impractical and prone to mistakes. Instead, we can use the help of computers to do the counting for us.
It's quite apparent that a quick and easy way to do this is utilizing nested for loops to repeatedly check the sum of the three dice and add the combination to an array if it equals 10.
wantedSum = 10; combinations = []; % Initialize empty array for i = 1:6 % Iterate through all possible combinations for j = 1:6 for k = 1:6 if i + j + k == wantedSum % If the sum matches newComb = sort([i,j,k]')'; % sort the combination % put the combination inside the array combinations = [combinations; newComb]; endif endfor endfor endfor
Before adding into the array, we sort the combination so we can take out the duplicates later. To compute the probability, we divide the total number of occurrences length(combinations) by the total number of possible events, .
% Probability of getting sum of 10 probTen = length(combinations) / 6^3; probText = ["The probability of getting " num2str(wantedSum) " as a sum is " num2str(probTen*100) "%%.\n"]; % Show probability as percentage printf(probText)
To display the combinations that result in a sum of 10, we can use the unique() function. This function searches for duplicates, deletes them and sorts the remaining entries in ascending order. The documentation for unique() can be found here.
printf("The valid combinations are: \n") disp(unique(combinations, "rows")); % Display unique combinations
As we don't need to show differently ordered, but otherwise identical combinations, this function is perfect for our purpose. The output of this script is:
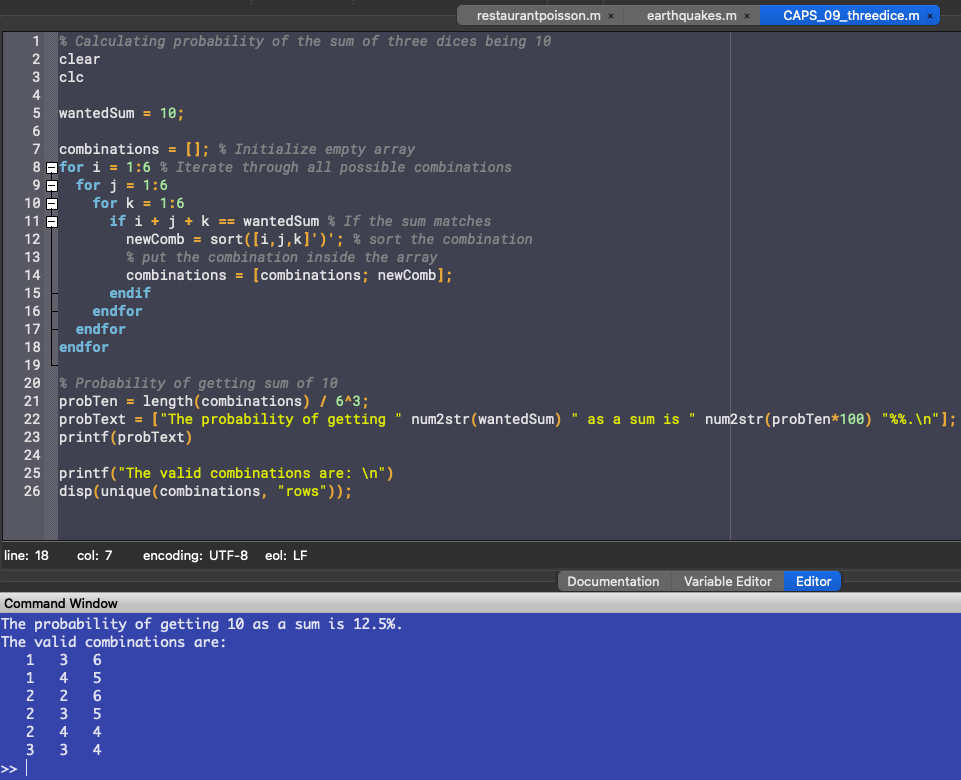
Comparing this to our earlier manual computation, we get the same result.